AVAILABLE 24x7
888.662.2724
AVAILABLE 24x7
(888) 66CARAH
Fast & Accurate
Request A Quote
Quick Response
Chat With Us



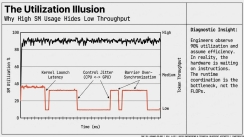
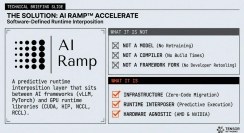
This slide explains that real-world LLM performance is limited more by coordination overhead than raw compute, highlighting bottlenecks like kernel launch serialization, collective communication stalls, memory contention, and over-synchronization. Together, these systemic inefficiencies can reduce achievable throughput by 30–60% compared to theoretical performance.

Download the Resource